
Jahrestagung der GAMM: Spannende Vorträge und Diskussionen in Dresden
Vom 30. Mai bis 2. Juni waren wir auf der Jahrestagung der Gesellschaft für angewandte Mathematik und Mechanik …
Vom 30. Mai bis 2. Juni waren wir auf der Jahrestagung der Gesellschaft für angewandte Mathematik und Mechanik …

Am 15. und 16. Mai 2023 fand die inzwischen elfte Auflage der Clusterkonferenz des microTEC Südwest e. V. statt …
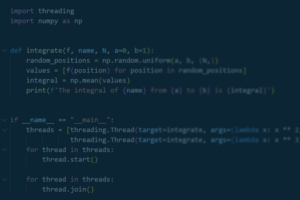
Interner Wissensaustausch ist ein wichtiger Faktor bei ATR Software. Deshalb haben wir die Vortragsreihe Wissen kompakt…

Für den Junior Wettbewerb der RoboCup Federation entwerfen, bauen und programmieren die Teams einen…

Heute stellen wir euch ein weiteres Projekt aus unserer Zusammenarbeit mit dem Dgitalisierungszentrum…

Bei strahlendem Sonnenschein machten wir uns an einem Nachmittag…

Heute stellen wir Ihnen DigiPrüF – die Digitale Prüfplattform für die Fahrzeug- und Zulieferindustrie vor. Ziel des …
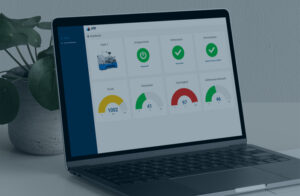
Wenn ein KI-System implementiert und live in Verwendung ist, erstellt es Vorhersagen…

Obwohl das Wetter erst nicht sehr vielversprechend aussah…
Sie sehen gerade einen Platzhalterinhalt von Vimeo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von hCaptcha laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von Turnstile laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr Informationen