Interner Wissensaustausch ist ein wichtiger Faktor bei ATR Software. Deshalb haben wir die Vortragsreihe Wissen kompakt ins Leben gerufen. Das ist eine Vortragsreihe, bei der jedes Teammitglied unkompliziert zum Vortragenden werden kann und hier eine Bühne bekommt, um das Fachwissen mit anderen zu teilen. Jedem Mitarbeitenden steht es dabei frei, bei Interesse an den Vorträgen teilzunehmen. Somit wird ein zwangloser und unkomplizierter Wissensaustausch ermöglicht.
Ein Beispiel gefällig? Der folgende Artikel ist eine grobe Zusammenfassung des Impulsvortrages Nebenläufigkeit in Python. Die Programmiersprache Python ist im Zuge unserer Aktivitäten im Bereich Machine Learning und Optimierung essenziell, weshalb sich unser KI-Team intensiv mit dieser Sprache beschäftigt.
Um was geht es?
Auch als parallele Programmierung bekannt, ist die Nebenläufigkeit eine wichtige Technik zur Optimierung der Leistung von Programmen. In Python gibt es verschiedene Möglichkeiten, um Nebenläufigkeit zu implementieren, darunter Multithreading, Multiprocessing und Coroutinen. In diesem Artikel werden wir uns diese Konzepte genauer ansehen und ihre Unterschiede sowie ihre Vor- und Nachteile diskutieren.
Leider muss zuerst gesagt werden, dass der Global Interpreter Lock (GIL), ein Mechanismus in CPython, die Ausführung von Python-Code auf einem einzigen Thread beschränkt. Dies bedeutet, dass Python-Code aufgrund des GIL nur sequenziell ausgeführt werden kann, auch wenn mehrere Threads vorhanden sind. Der GIL verhindert somit eine echte Nebenläufigkeit in Python, da mehrere Threads nicht gleichzeitig auf verschiedene Prozessorkerne zugreifen und somit eine gleichzeitige Ausführung von Code auf mehreren Kernen nicht möglich ist.
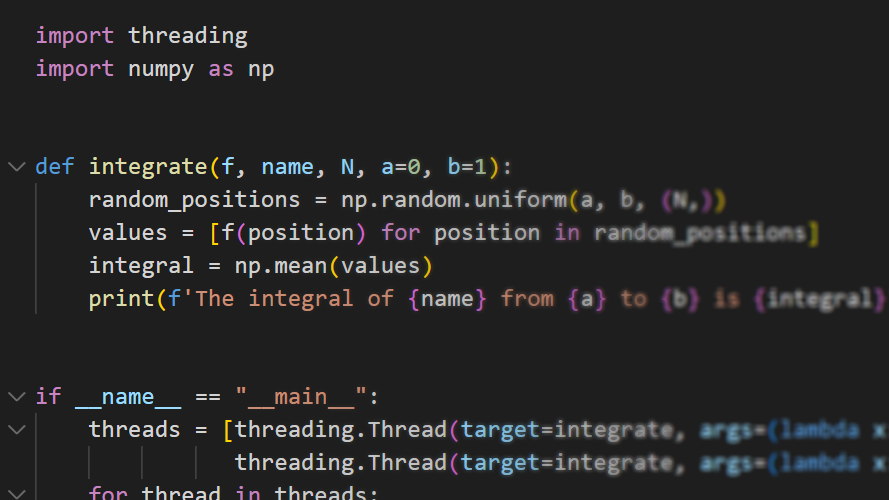
Multithreading in Python
Multithreading bezieht sich auf die Ausführung von mehreren Threads innerhalb eines einzigen Prozesses. Ein Thread ist eine leichtgewichtige Unterbrechung eines Programms, die unabhängig von anderen Threads ausgeführt werden kann. Ein Prozess kann mehrere Threads haben, die alle im selben Speicherbereich arbeiten. Python verfügt über eine integrierte Thread-Unterstützung, die das Erstellen und Ausführen von Threads sehr einfach macht.
Beispiel für Multiprocessing in Python:
import threading
def print_numbers():
for i in range(10):
print(i)
def print_letters():
for i in range(ord('a'), ord('k')):
print(chr(i))
t1 = threading.Thread(target=print_numbers)
t2 = threading.Thread(target=print_letters)
t1.start()
t2.start()
t1.join()
t2.join()
In diesem Beispiel werden zwei Prozesse erstellt, die jeweils eine Funktion ausführen, um Zahlen und Buchstaben auszudrucken. Die Zeile if __name__ == ‚__main__‘: stellt sicher, dass der Code nur ausgeführt wird, wenn das Skript als Hauptprogramm ausgeführt wird, anstatt von einem anderen Skript importiert zu werden. Der Code p1.start() und p2.start() starten die Prozesse, und der Code p1.join() und p2.join() stellt sicher, dass die Prozesse abgeschlossen sind, bevor das Programm beendet wird.
Multiprocessing hat den Vorteil, dass es einfacher zu debuggen ist als Multithreading, da jeder Prozess seinen eigenen Speicherbereich hat und es keine Race Conditions gibt. Allerdings ist es auch etwas langsamer als Multithreading, da das Erstellen und Beenden von Prozessen etwas mehr Zeit in Anspruch nehmen.
Coroutinen in Python
Coroutinen sind eine andere Art der Nebenläufigkeit, die in Python verwendet werden können. Coroutinen sind Funktionen, die gestartet werden können und später wieder aufgenommen werden können, ohne dass ein neuer Thread oder Prozess gestartet werden muss. Python verfügt über eine integrierte Unterstützung für Corutinen in Form von Generator-Objekten und asynchronen Funktionen.
Beispiel für Coroutinen in Python:
import multiprocessing
def print_numbers():
for i in range(10):
print(i)
def print_letters():
for i in range(ord('a'), ord('k')):
print(chr(i))
if __name__ == '__main__':
p1 = multiprocessing.Process(target=print_numbers)
p2 = multiprocessing.Process(target=print_letters)
p1.start()
p2.start()
p1.join()
p2.join()
In diesem Beispiel werden zwei Coroutinen erstellt, die jeweils eine Funktion ausführen, um Zahlen und Buchstaben auszudrucken. Der Code asyncio.sleep(1) sorgt dafür, dass jede Coroutine eine Sekunde lang pausiert, bevor sie die nächste Zahl oder den nächsten Buchstaben ausdruckt. Der Code asyncio.gather(print_numbers(), print_letters()) stellt sicher, dass beide Coroutinen parallel ausgeführt werden.
Coroutinen haben den Vorteil, dass sie sehr effizient sind und keine zusätzlichen Threads oder Prozesse benötigen. Sie sind auch sehr einfach zu debuggen, da sie sequenziell ausgeführt werden. Allerdings sind sie möglicherweise nicht die beste Wahl für Aufgaben, die eine intensive CPU-Nutzung erfordern, da sie nur auf einem CPU-Kern ausgeführt werden.
Fazit
In Python gibt es verschiedene Möglichkeiten, um Nebenläufigkeit zu implementieren, darunter Multithreading, Multiprocessing und Coroutinen. Jede dieser Methoden hat ihre eigenen Vor- und Nachteile. Die Wahl der Methode hängt von der spezifischen Anwendung ab. Multithreading ist gut geeignet für Anwendungen, die viele Eingabe- beziehungsweise Ausgabeoperationen ausführen, während Multiprocessing besser für Anwendungen geeignet ist, die eine intensive CPU-Nutzung erfordern. Coroutinen wiederum sind eine gute Wahl für Anwendungen, die viele Aufgaben mit wenig CPU-Nutzung ausführen müssen.
Es ist wichtig zu beachten, dass Nebenläufigkeit in Python einige Fallstricke haben kann, insbesondere wenn mehrere Threads oder Prozesse auf gemeinsame Ressourcen zugreifen. Um Probleme zu vermeiden, sollten Sie immer sicherstellen, dass der Zugriff auf gemeinsame Ressourcen durch Verwendung von asynchronen Mechanismen synchronisiert ist.
Wollen Sie tiefer in das Thema eintauchen? Wir empfehlen die Lektüre der Tutorials von Jason Brownlee https://superfastpython.com/tutorials/



