
Die OWASP Top 10 – Eine Checkliste für IT Security
Die Angriffe auf IT-Infrastrukturen verschiedener Anbieter häufen sich…
Die Angriffe auf IT-Infrastrukturen verschiedener Anbieter häufen sich…

Das Erkennen von Objekten ist ein großes Thema in der Produktion. Ein Anwendungsfall ist zum Beispiel …
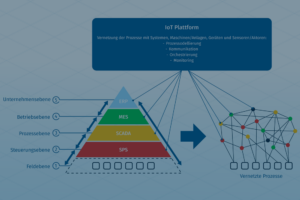
Intelligenter produzieren bedeutet häufig auch vernetzter produzieren.In diesem Beitrag stellen wir …

Warum Optimierung? Optimierungsmethoden spielen in der Produktion eine entscheidende Rolle, da sie dazu beitragen …

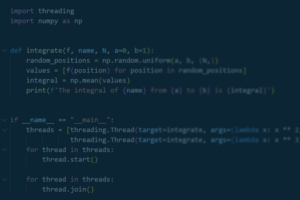
In diesem Artikel demonstrieren wir die Anwendbarkeit von Deep Learning für die Anomalieerkennung…

Vom 30. Mai bis 2. Juni waren wir auf der Jahrestagung der Gesellschaft für angewandte Mathematik und Mechanik …

Am 15. und 16. Mai 2023 fand die inzwischen elfte Auflage der Clusterkonferenz des microTEC Südwest e. V. statt …
Interner Wissensaustausch ist ein wichtiger Faktor bei ATR Software. Deshalb haben wir die Vortragsreihe Wissen kompakt…

Heute stellen wir euch ein weiteres Projekt aus unserer Zusammenarbeit mit dem Dgitalisierungszentrum…
Sie sehen gerade einen Platzhalterinhalt von Vimeo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von hCaptcha laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von Turnstile laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr Informationen