Letztes Jahr fanden in Berlin wieder die mehrtägigen JavaScript Days statt.
Erfahrene Entwickler, Trainer, Berater und Freiberufler stellten im Rahmen von diversen Workshops ihr Wissen den Teilnehmern zur Verfügung und behandelten aktuelle Themen zu den Webentwicklungsbereichen – JavaScript, Angular, React, RxJS, Redux, Web Components, Node.js und mehr. Für die ATR Software GmbH waren vor allem die Themen im Bereich von Angular und TypeScript interessant.
Für Einsteiger bot sich der ganztägige Kurs „Angular – von 0 auf 100“ sehr an, bei dem es nicht nur um die Vermittlung von Basiswissen ging, sondern auch „Best Practice“ – Methoden zusammengefasst wurden, um von Anfang an die korrekte Implementationsmethodik anwenden zu können.
Darüber hinaus gab es viele weitere Workshops, die sich mit den zuvor genannten Themen befassten.
Es gab je einen Workshop zum Thema „Testing“ mit JavaScript, Angular und React. Einige Deep Dive Workshops und Informationen zu Neuheiten der aktuellen Versionen der Frameworks und Entwicklungssprachen.
Zu einem der eindrucksvollsten Vorträgen gehört aus unserer Sicht der Votrag „Navigationsstrukturen mit dem Angular Router: Deep Dive“ von Manfred Steyer (https://www.softwarearchitekt.at/), in dem an Hand von kleinen Beispielen gezeigt wird, welche komplexen Sachverhalte (z.B. MessageBoxen) mit dem Router gelöst werden können.
Wissen, das wir in allen unseren Web-Projekten sofort anwenden konnten, hat uns der Votrag „Hochperformante Single Page Applications mit Angular“ vermittelt. Von LazyLoading über Precaching bis hin zu Service Workern hat der Vortrag verschiedenste Techniken für bessere Performance demonstriert, welche gleichzeitig alle auch direkt über die Angular CLI mühelos einbindbar sind.
Teilnehmer: Philipp Freibauer Bogdan Tamrasov Emmanuel Schwartz
https://www.atr-software.de/wp-content/uploads/2019/06/jsStock.jpg19202560Burkhardhttps://www.atr-software.de/wp-content/uploads/2017/03/Logo-RGB_Web-Header.pngBurkhard2019-06-01 21:17:192022-02-25 16:05:37JavaScript/Angular Days 2018
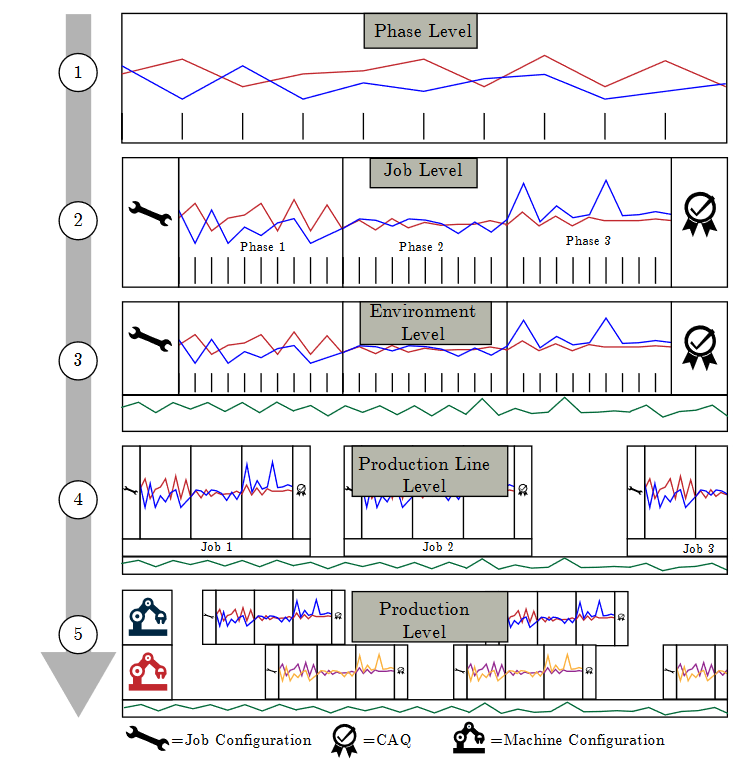
Mit unserem Beitrag Towards a Hierarchical Approach for Outlier Detection in Industrial Production Settings nahmen wir am ersten Internationalen Workshop zum Thema Data Science in der Industrie 4.0 in Lissabon teil. Unsere Grundsätzliche Fragestellung lautetete: Wie kann man Unregelmäßigkeiten innerhalb einer vielschichtigen Produktion gut darstellen. Hierfür entwickelten wir ein Ebenenmodell (siehe Bild), auf dem wir unsere Thesen aufbauten. Dabei sind drei grundsätzliche Ideen enthalten:
Wenn eine Unregelmäßigkeit auch nach einer Aggregation der Daten (Durchschnitt, Summe etc…) noch auffindbar ist, wird sie als wichtiger dargestellt.
Ausreißer, die an mehreren Sensoren gleichzeitig festgestellt werden (Support), sind wichtig.
Die Stärke eines Ausreißer ist immer relativ zu den anderen Ausreißern derselben Maschine.
Aus diesen drei Erkenntnissen wurde ein Algorithmus aufgebaut, der wiederum hilft Unregelmäßigkeiten besser zu vergleichen und einzuordnen.
Unser Ebenenmodell
Weitere Vorträge widmeten sich u.a. dem so genannten ‚checkpointing‘ beim Streamen großer Daten. Hierbei wird ein Marker im Stream mitgesendet um, bei Ausfall des Systems, keine Daten zu verlieren. Im Bereich Data Analytics widmete sich ein Ansatz den Gauß’schen Prozessen, die auf dem Prinzip der Regression arbeiten und trotzdem ein Konfidenzintervall für ihre Vorhersage anbieten.
Die Konferenz widmete sich nicht nicht nur aktuellen Entwicklungen, sondern schaute auch vergleichend in die Vergangenheit um festzustellen, welche Theorien den „Test der Zeit“ bestanden haben. Hierbei zeichnete sich vor allem Amdahls Law aus, welches besagt, das ein System nur so skalierbar ist, wie die am wenigsten skalierbare Komponente.
https://www.atr-software.de/wp-content/uploads/2019/03/dsi4_blue.png408800Burkhardhttps://www.atr-software.de/wp-content/uploads/2017/03/Logo-RGB_Web-Header.pngBurkhard2019-03-28 20:54:112022-02-25 16:04:32Erster ‚International Workshop on Data Science for Industry 4.0‘
Nach dem erfolgreichen Hackathon im Dezember letzten Jahres auf der Reisensburg in Günzburg beschlossen wir eine hausinterne Wiederholung dieses spannenden Konzeptes. Bei einem Hackathon, also einer Mischung aus Marathon und Hacken, wird innerhalb von kurzer Zeit versucht für ein Thema Lösungen zu entwickeln. Diese Herangehensweisen an Ideen wird oftmals als sportliches Event gesehen, bei dem auch Preisgelder für die beste, entwickelte Lösung ausgeschrieben werden. Bei uns jedoch stand der explorative Gedanke im Vordergrund. Zwei Tage lang konnten wir, unabhängig von den Themen des Tagesgeschäftes, Konzepte und Technologien erproben. Hier eine Auswahl unserer spannenden Themen:
Das Bitcoin Fahrrad – Radel dich reich!
Der Gedanke vom schnellen Geld ist für viele Menschen verlockend. Der Gedanke, dass man für das schnelle Geld auch schnell im sportlichen Sinne sein muss, lässt eher die fitnessbegeisterten Menschen jubeln. Wir präsentieren: Das Bitcoinfahrrad. Über den Fahrraddynamo werden Raspberry PIs (Einplatinencomputer) betrieben, die Bitcoins produzieren. In der Theorie zumindest. In der Praxis benötigt man hunderttausende Jahre um zum Bitcoin Millionär aufzusteigen.
Strampeln für Geld – Das Bitcoin Fahrrad
Computer Vision auf verschiedenen Plattformen
Ein zweites Team beschäftigte sich mit der Anwendung der Computer Vision Bibliothek OpenCV auf verschiedenen Plattformen. Sie testeten u.a. Gesichtserkennungsalgorithmen und probierten die Umsetzung der Anwendung in verschiedenen Programmiersprachen.
Die Silhuette eines Programmierers
Ein Chatbot für Maschinendaten
Sie sind inzwischen weit verbreitet im Internet: Chatbots, die u.a. unsere Bestellungen aufnehmen und den Kundensupport vermitteln. Wir verwendeten das Framework Dialogflow von Google und Amazons Alexa um Maschinendaten abzufragen. Die Abfrage ist entweder über Text- oder Spracheingabe möglich und besonders bei der Kommunikation mit Alexa sind lustige Sprachmissverständnisse praktisch vorprogrammiert.
„Alexa, wie ist der aktuelle Zustand der Maschine?“
Weitere Gruppen beschäftigten sich mit Clustertechnologien, einer Zeiterfassungssoftware im Web und dem Framework JHipster.
Die rauchenden Köpfe konnten mit kühlem Bier abgekühlt werden und eine kleine Vortragsreihe zu freien Themen (z.B. NGRX, Quantencompter) rundete unseren Hackathon ab.
https://www.atr-software.de/wp-content/uploads/2019/02/bitcoinfahrrad_blau.png31204160Burkhardhttps://www.atr-software.de/wp-content/uploads/2017/03/Logo-RGB_Web-Header.pngBurkhard2019-02-18 07:53:112022-02-25 16:04:13Hackathon II: Von Fahrrädern und gesprächigen Computern
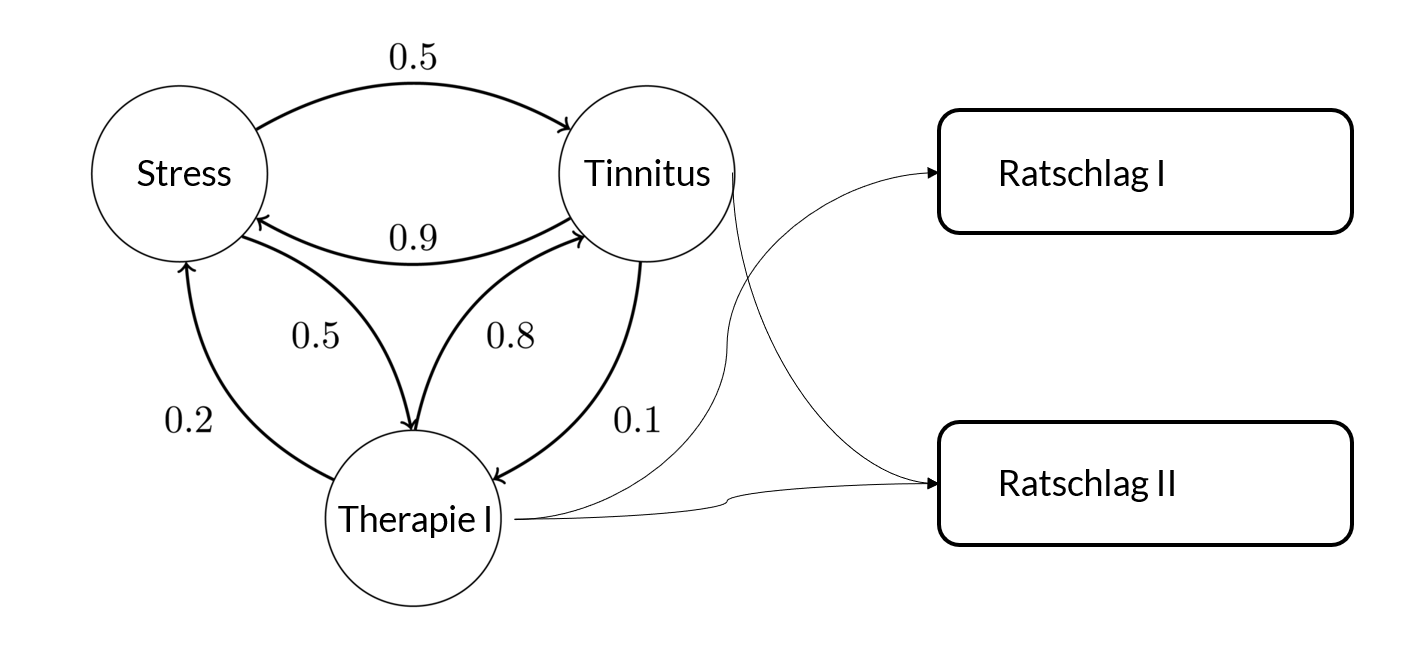
Im Rahmen der Kooperation zwischen der ATR Software GmbH und dem Institut für Datenbanken und Informationssysteme hielt Burkhard Hoppenstedt eine Gastvorlesung „Maschine Learning auf medizinischen Daten“. Neben konkreten Fallbeispielen aus medizinischen Projekten an der Universität Ulm bot die Vorlesung vor allem einen Überblick über Ansätze zur künstlichen Intelligenz und einige ausgefallene Fragestellungen:
Wie funktioniert eigentlich das Empfehlungssystem von Amazon?
Wie bringt man einen Computer dazu ein Computerspiel ohne jegliches Vorwissen zu meistern?
Wie clustert man einen Hörsaal (als Liveexperiment)?
Zusätzlich wurden Live-Beispiele gezeigt, bei denen ein Datensatz mit Python, Sci-Kit und Matplotlib analysiert wurde.
Wir danken Herrn Dr. Pryss für seine Einladungen und den Studenten für ihr reges Interesse. Auch im kommenden Semester werden wir uns wieder mit einem Gastvortrag an der Lehre beteiligen.
https://www.atr-software.de/wp-content/uploads/2019/02/hmmtinnitus_blau.png6501418Burkhardhttps://www.atr-software.de/wp-content/uploads/2017/03/Logo-RGB_Web-Header.pngBurkhard2019-02-08 14:02:182022-02-25 16:03:55Gastvorlesung zu Maschinellem Lernen
Gegensätzlicher kann eine Kulisse kaum sein: vom 06. auf den 07. Dezember 2018 trafen sich 30 Teilnehmer aus Industrie und Wissenschaft vor mittelalterlicher Kulisse auf Schloss Reisensburg in Günzburg, um digitale Lösungen aus dem Bereich Industrie 4.0 zu entwickeln.
Als Gastgeber stellten das Institut für Datenbanken und Informationssysteme (DBIS), Uhlmann Pac-Systeme GmbH & Co. KG (Laupheim), ATR Software GmbH (Neu-Ulm) in Kooperation mit den Instituten Medieninformatik, Neuroinformatik, Organisation und Management von Informationssystemen der Universität Ulm sowie dem Zentrum für Sonnenenergie- und Wasserstoff-Forschung (ZSW) den Teilnehmern knifflige Fragestellungen aus ihrem Forschungs- und Arbeitsleben.
Schloss Reisensburg – idyllische Lage in Günzburg
Der Hackathon gliederte sich in die vier Themenfelder Mensch-Maschine Interaktion, Datenanalyse, IoT Device Management und Digitale Geschäftsmodelle. In einer offenen Arbeitsweise tauschten sich hier Studierende, Wissenschaftler und Industrieexperten aus, und entwickelten in kurzer Zeit Konzepte und Software-Prototypen anhand realer Anwendungsfälle.
Ein spannendes neues Thema aus dem Themenfeld Mensch-Maschine Interaktion, die Arbeit mit Datenbrillen, zeigte Burkhard Hoppenstedt, Mitarbeiter des Instituts DBIS. Getrieben durch die jüngste, technische Weiterentwicklung wurden beispielsweise auf Basis der Microsoft HoloLens realistische Hologramme einer Brennstoffzelle zur Darstellung des Elektronenflusses entwickelt. Die Teilnehmer konnten hierbei auf reale Daten und wissenschaftliche Expertise von Michael Schmid zurückgreifen, der Mitarbeiter am ZSW Baden-Württemberg ist und sich auf die Optimierung von Brennstoffzellen spezialisiert hat.
Der Bereich der Datenanalysen profitiert von den Entwicklungen im IT-Bereich “Big Data”, also der Disziplin zur Bearbeitung großer Datenmengen. Im Rahmen des Hackathons wurden Mustererkennungsalgorithmen auf Sensordaten einer Uhlmann Pharmaverpackungsmaschine angewendet. Federführend waren hierbei Steffen Stökler, Datenanalyst bei Uhlmann sowie Viktor Kessler, Mitarbeiter des Instituts Neuroinformatik.
Mit Hilfe des entwickelten Prototypen wurde gezeigt, dass sich mit Hilfe erkannter Abweichungen auf solchen Sensordaten vorausschauende Erkenntnisse über Maschinen ableiten lassen. Dies ermöglicht neue Anwendungsfelder, wie die vorausschauende Wartung (Predictive Maintenance), an der auch ATR und Uhlmann forschen.
Data Analytics – Einblick in eine Maschine
Im Themenfeld der IoT Device Connectivity wurden Themen und Konzepte zur Anbindung von industriellen Maschinen, wie z.B. Uhlmann Pharmaverpackungsmaschinen, an verschiedene Cloud Infrastrukturen betrachtet. Im Rahmen des Hackathons zeigte Klaus Kammerer, Mitarbeiter des Instituts DBIS, anhand der Fischertechnik-Simulationsfabrik „DBISFactory“ Fragestellungen wie zu verwendende Kommunikationsprotokolle, Datenmodelle und Software Architekturen auf. Hierbei unterstützte Christopher Hauser, Mitarbeiter des Instituts OMI, durch interessante Einblicke in Cloud Architekturen und Technologien.
Durch die fortschreitende Digitalisierung eröffnen sich auch neue digitale Geschäftsmodelle. So könnten beispielsweise in naher Zukunft Maschinen eines Maschinenbauers nicht mehr verkauft, sondern nur verliehen werden; der Nutzer zahlt dann nur die tatsächliche Benutzung (engl.: pay-per-use). Im Rahmen des Hackathons führte Melanie Ruf, Spezialistin für digitale Geschäftsmodelle bei Uhlmann, in die verschiedenen digitalen Geschäftsmodelle ein. Birgit Stelzer, Leiterin der Arbeitsstelle für Hochschuldidaktik der Universität Ulm, unterstützte mit umfangreicher Erfahrung zur Entwicklung solcher Methoden. Den Teilnehmern wurde ein grundlegendes Verständnis für die Modellierung digitaler Geschäftsmodelle näher gebracht, das sie anschließend beispielhaft in einem Planspiel umgesetzt haben.
Umrahmt wurde der Hackathon von sozialen Events. Das Interesse und Engagement der Teilnehmer übertraf dabei alle Erwartungen; sie tüftelten und diskutierten bis spät in die Nacht an ihren Lösungen.
Alexander Treß, Geschäftsführer von ATR nahm selbst am Hackathon teil und war erfreut über die vielfältigen Themen: “Die Entwicklungen aus dem Themenfeld Industrie 4.0 bieten viele spannende Möglichkeiten um produzierenden Unternehmen ihren Arbeitsalltag zu erleichtern und Werte zu schaffen. Wir freuen uns, gemeinsam mit der Universität Ulm und der Firma Uhlmann, im Rahmen des Hackathons neue Ideen zu entwickeln und vorhandene Ansätze zu testen.”
„Der Hackathon ist für uns eine hervorragende Möglichkeiten mit den Studierenden an sehr praxisnahen Themen und Aufgabenstellungen aus einem Industrieunternehmen zu arbeiten und neue Lösungsansätze zu kreieren”, so Kathrin Günther, Leiterin des Digital Labs von Uhlmann. “Wir freuen uns daher sehr, dass solch eine Veranstaltung in Zusammenarbeit mit der Universität Ulm und der Firma ATR möglich war.“
Es gibt bereits Überlegungen diese Format weiterzuführen, so dass Studierende und Interessierte auf weitere interessante Einblicke in die industrielle Praxis gespannt sein dürfen.
Im September 2018 fand in Budapest im Rahmen einer Konferenz zum Thema Simulation die International Conference of the Virtual and Augmented Reality in Education statt. In diesem Beitrag werden nun drei Ideen und Projekte aus dieser Konferenz vorgestellt.
Im Feld von Design und Architektur wird Augmented Reality bereits seit einigen Jahren erfolgreich eingesetzt. Hierbei werden Entwürfe z.B. mittels AR Brillen betrachtet um ein besseres Gefühl für die Positionierung von Elementen im Raum zu erhalten. In einer Studie wurde gezeigt, dass diese Techniken einen Geschwindigkeits und Effektivitätsvorteil bieten [1].
Eine Forschergruppe aus Thailand entwickelte einen Ansatz, der es erlaubt Zeichnungen sehr schnell in 3D Modelle und damit in die virtuelle Welt zu transferieren. Ihren Anwendungsfall zeigten sie mit Hilfe von Fischzeichnungen, die in einem Virtuellem Aquarium zu leben erweckt wurden. [2]
Der letzte Ansatz beschreibt die Virtual Quality Toolbox, eine VR Anwendung, die es Angestellten in einer kleinen Produktion sehr einfach ermöglicht QS mit Virtual Reality zu bearbeiten. Hierbei werden vor allem Control-Charts, Histogramme, Paretodiagramme und Fishbone Diagramme (Ursache-Wirkungs-Diagramme) eingesetzt. [3]
——————————
[1] González et al.: The Impact of New Technologie in Design Education
[2] Boonbrahm et al.: Virtual Aquarium: Tool for Science Motivation using Augmented Reality
Dieser Blogartikel ist ein Gastbeitrag unseres Praktikanten Julian Henning, der sich auf der data2day 2018 in einem Workshop mit dem Thema Machine Learning beschäftigte.
Themen wie Big Data und Machine Learning spielen für ATR eine immer größere Rolle. Kombiniert wurden diese beiden Themenbereiche bei dem Workshop „Machine Learning mit PySpark“, welcher im Rahmen der data2day Konferenz in Heidelberg stattfand.
In der ersten Hälfte des Workshops wurden zunächst die grundlegenden Konzepte von Apache Spark vorgestellt, anschließend wurden die ersten Aufgabestellungen praktisch gelöst. Alle Aufgaben im Rahmen des Workshops waren in Jupyter Notebooks integriert, welche auf Amazon Webserver liefen. Dadurch konnte ein gängiger Webbrowser als Entwicklungsumgebung eingesetzt werden, ohne Python oder Ähnliches installieren zu müssen.
Der Workshop drehte sich in der zweiten Hälfte hauptsächlich um Machine Learning. Nachdem die grundlegenden Begriffe sowie die lineare Regression erklärt wurden, konnte mit Hilfe von PySpark ein erstes Model trainiert werden. Im Laufe des Workshops wurde hieraus eine Spark ML Pipeline entwickelt.
Als zweites Beispiel wurde eine Sentiment-Analyse umgesetzt. Hierbei konnten die Teilnehmer eine eigene Pipeline implementieren, die Kundenbewertungen verarbeitet und aus den verwendeten Wörtern auf eine positive oder negative Rezession schließt.
Dieser Artikel bezieht sich auf einen Teilaspekt eines Vortrages im Rahmen des Arbeitskries 4.0 zum Thema „Verteilte Datenanalysen“. In diesem Vortrag wurden Techniken zur Datenanalyse für große Datenmenge u.a. mit der Datenbank MongoDB und dem Framework Apache Spark demonstriert. Im folgenden wird anhand eines vereinfachten Beispieles ein Paradigma für die verteilte Datenverarbeitung beschrieben.
Stellen Sie sich folgendes vor: Sie nehmen an einem sehr produktivem Workshop teil. Die Teilnehmer werden in verschiedene Gruppen aufgeteiltl, die sich in ihre separaten Arbeitsräume zurückziehen um dort ihre Lösungen zu erarbeiten. Sie sind so in ihre Arbeit vertieft, dass der Workshopleiter beschließt Pizza zu bestellen. Er gibt in jeden Raum einen Zettel mit der Bitte den Namen des Teilnehmers und die gewünschten Pizzastücke zu notieren.
Um eine Abrechnung zu vereinfachen soll die Pizza für Teilnehmer aus einem anderen Geldtopf bezahlt werden als die Mitarbeiterpizza. Aus diesem Grund beschließen zwei Mitarbeiter sich die Arbeit zu teilen: Ein Mitarbeiter schreibt alle Teilnehmer auf seine Zettel und der andere Mitarbeiter notiert sich die Mitarbeiterbestellungen.
In einem letzten Schritt summiert jeder der bearbeitenden Mitarbeiter seine Zahlen auf und gibt die Bestellung auf.
In diesem Beispiel stecken die drei Kernkonzept des MapReduce Paradigmas, das von Google eingeführt wurde. In Phase I (Map) werden Wertepaare aus einem eindeutigen Identifizierer (Key) und dem zugehörigen Wert (Value) gebildet. Die Sortierung der <key, value> Einträge nach ihrer Zugehörigkeit ergibt Informationsblöcke mit passenden Informationen, die als Datenstruktur für das lokale Arbeiten optimal sind, weil sie nicht über das Netzwerk verteilt sind. Diese Phase II wird Shuffle genannt. In der finalen Phase III (Reduce) wird definiert wie diese Informationsblöcke zusammengefasst werden sollen.
Das Ergebnis ist eine schnelle Datenverarbeitung von großen Datenmengen. Oder eben eine Pizza. Guten Appetit!
Deep Learning gehört zu den großen Hype-Themen der künstlichen Intelligenz. Besonders im Bereich Computer Vision, zu dem z.B. das Themengebiet Bilderkennung gehört, leistet diese Technik bahnbrechendes. Das Besondere an dieser Datenstruktur ist, dass man, im Gegensatz zu früheren Herangehensweisen, keine bestimmten Merkmale im Bild spezifiziert. Durch die Kombination verschiedener Filter und durch das Unterteilen des Bildes in kleinere Segmente, die wieder zusammengeführt werden, entdeckt das Netz seine eigene Repräsentation.
Hier wollen wir kurz zwei Anwendungen vorstellen, bei denen man sich in einer Webanwendung von der Mächtigkeit dieser Technologie überzeugen kann.
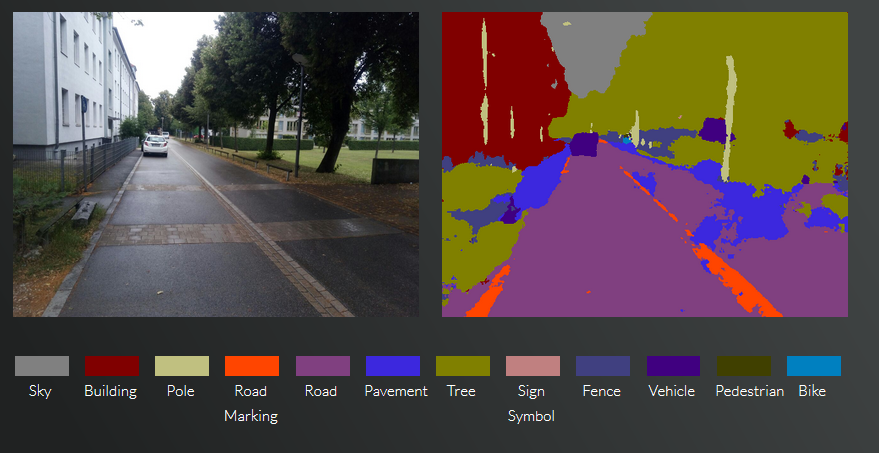
Automatische Segmentierung eines Bildes
Forscher der Universität Combridge haben in ihrem Projekt SegNet, ein Neuronales Netz darauf trainiert in einem Foto die Bereiche zu unterteilen. Wir haben ein Foto vor unserer Haustür gemacht und die Ergebnisse sind wirklich beeindruckend. Das Netz erkennt ein parkendes Auto, die Häuserreihe auf der linken Seite, die Bäume und auch die Straße.
Link: http://mi.eng.cam.ac.uk/projects/segnet/demo.php#demo
Zeichnungen Erkennen
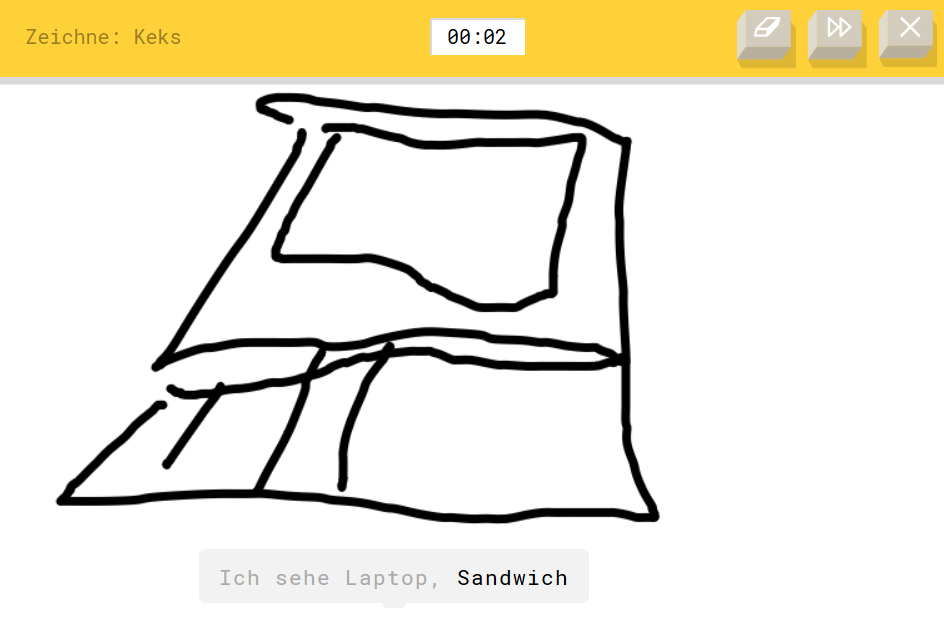
Google zeigt in seiner Anwendung Quickdraw, dass nicht nur Fotos eingeordnet werden können. Wer also gerade keine Kamera zur Hand hat und kein Stockfoto segmentieren lassen will, kann sich hier mit einem digitalen Stift austoben. Unser Testzeichner hat, um das System zu testen, natürlich keinen Keks gemalt, sondern einen Laptop. Und dieser ist noch nicht mal schön, sondern krumm und schief; mit überlappenden Linien. Trotzdem erkennt das Netz den Laptop. Es könnte aber auch ein Sandwich sein.
Link: https://quickdraw.withgoogle.com/#
Das Thema Data Science nimmt in Unternehmen, in Instituten und auch bei Data Nerds einen immer größeren Stellenwert ein. Folgerichtig war es nur eine Frage der Zeit bis sich eine Gruppe aus Interessierten Datenwissenschaftler in Ulm bildete. Im ersten großen Treffen bei Daimler TSS trafen sich knapp 40 Interessierte.
In einem ersten Vortrag unter dem Titel „AI for Car Diagnostics – from Lab to Worldwide Use“ erzählte Dr. Valentin Zacharias von Daimler TSS von der Entwicklung des Themas Data Science in seinem Betrieb. Nach diesem konzeptionellen Vortrag tauchte Dr. Simon Müller von AnoFox tief in die Methoden des maschinellen Lernens in seinem Vortrag „Unsupervised Anomalieerkennung und Vorhersage von Zeitreihen im Unternehmenskontext“ ein.