
Gutes Holz, schlechtes Holz?
Holz ist weltweit einer der wichtigsten nachwachsenden Rohstoffe. Durch Fotosynthese…
Holz ist weltweit einer der wichtigsten nachwachsenden Rohstoffe. Durch Fotosynthese…

Im Rahmen des Arbeitskreises Industrie 4.0 stellten Wissenschaftler der Universität Ulm ihre Forschung zu Servicerobotern vor. Anschauungsobjekt ist ein humanoider Roboter namens Pepper (siehe Foto). Pepper
Auf dem 5. Serviceforum der Region Stuttgart trafen sich am 03. Juli 2019 Entscheider im Servicegeschäft von Maschinen- und Anlagenbauern um Denkanstöße zu sammeln und zu

Salento, auch bekannt als der Absatz des Stiefels von Italien, ist eigentlich nicht für seine hochmoderne Technologie bekannt. Vielmehr prägen Architektur, Strand und Tourismus das alltägliche
Letztes Jahr fanden in Berlin wieder die mehrtägigen JavaScript Days statt. Erfahrene Entwickler, Trainer, Berater und Freiberufler stellten im Rahmen von diversen Workshops ihr Wissen den

Mit unserem Beitrag Towards a Hierarchical Approach for Outlier Detection in Industrial Production Settings nahmen wir am ersten Internationalen Workshop zum Thema Data Science in der Industrie

Nach dem erfolgreichen Hackathon im Dezember letzten Jahres auf der Reisensburg in Günzburg beschlossen wir eine hausinterne Wiederholung dieses spannenden Konzeptes. Bei einem Hackathon, also einer
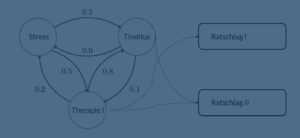
Im Rahmen der Kooperation zwischen der ATR Software GmbH und dem Institut für Datenbanken und Informationssysteme hielt Burkhard Hoppenstedt eine Gastvorlesung „Maschine Learning auf medizinischen Daten“.

Gegensätzlicher kann eine Kulisse kaum sein: vom 06. auf den 07. Dezember 2018 trafen sich 30 Teilnehmer aus Industrie und Wissenschaft vor mittelalterlicher Kulisse auf Schloss
Sie sehen gerade einen Platzhalterinhalt von Vimeo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von hCaptcha laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von Turnstile laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr Informationen