
In diesem Artikel demonstrieren wir die Anwendbarkeit von Deep Learning für die Anomalieerkennung in Bildern. Unser Ziel ist es, mit Hilfe von Neuronalen Netzen mögliche Fehler am Aufbau eines Vespa-Modells aus Klemmbausteinen zu erkennen.
Bei der Erkennung von Anomalien handelt es sich um die Bestimmung von Abweichungen oder Unregelmäßigkeiten in den Daten, die nicht dem erwarteten Muster oder Verhalten entsprechen. Das ist eine wichtige Aufgabe in vielen Bereichen wie Betrugsprävention, Systemüberwachung und Qualitätssicherung.
Mit diesem Use Case adressieren wir Explainable AI und machen unser System für die Anwender verständlich. Zudem stärken wir das Vertrauen in KI-Lösungen, die für Außenstehende oftmals wie eine Art Blackbox wirken.
Der erste Ansatz
Zuerst verwendeten wir einen Autoencoder, eine Art neuronales Netz, das Eingabedaten komprimiert und rekonstruiert. Anomalien können erkannt werden, indem man den Rekonstruktionsfehler misst, der die Diskrepanz zwischen Eingabe und rekonstruiertem Ausgang darstellt. Instanzen mit hohen Rekonstruktionsfehlerwerten sind wahrscheinlich Anomalien. In unserem Blog-Artikel KI-gestützte Fehlererkennung bei einem Vespa-Modell erklären wir die Funktionsweise genauer. Obwohl mit Autoencodern schon gute Ergebnisse erzielt werden können, sind in jüngster Vergangenheit einige noch fortschrittlichere, komplexere KI-Architekturen entwickelt worden. Diese bauen auf dem gleichen Prinzip auf, haben es aber weiter optimiert. Deshalb testeten und verglichen wir viele dieser neuen Ansätze für unseren Anwendungsfall.

Optimierung des Modells
Wir entschieden uns für Reverse Distillation in Kombination mit One-Class Bottleneck Embedding (OCBE), um eine bessere Effizienz und Effektivität zu erreichen. Diese Methode liefert eine sehr gut interpretierbare Darstellung der Daten und ermöglicht eine verbesserte Generalisierung für unbekannte Anomalien. Stark vereinfacht ausgedrückt erreicht sie diese bessere Performance durch das Vergleichen von Input und Output, ähnlich dem Prinzip eines Autoencoders. Jedoch findet dies auf verschiedenen Stufen der Codierung und Decodierung der Daten gleichzeitig statt. Ähnlich vielversprechende Ergebnisse ließen sich mit der PatchCore-Architekur erreichen, die sich auf die Rekonstruktion lokaler Patches konzentriert und somit kleinere lokale Anomalien besser erkennen kann
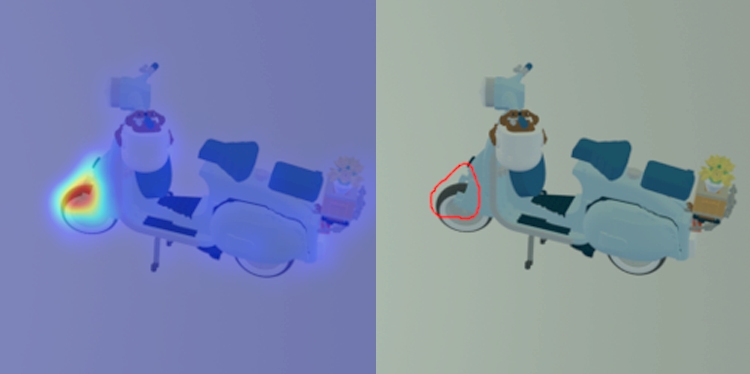
Anschließend optimierten wir unser Modell mit Methoden wie der Kreuzvalidierung, die wir während der Auswahl der besten Architektur und Parameter verwendeten, um besonders das häufige Problem von Overfitting zu vermeiden. Mithilfe von Transfer Learning konnten wir Gebrauch von sehr leistungsstarken, auf riesigen Datenmengen trainierten Bild-Klassifizierungs-Modellen machen, um die Anzahl der benötigten Trainingsdaten möglichst gering zu halten.
Nach sorgfältiger Anpassung unseres Modells auf die in Blender modellierten 3D-Grafiken testeten wir es mit Fotos der realen Lego-Vespa. Dabei bemerkten wir, dass Unterschiede in der Beleuchtung bei der Datenaufnahme das Modell verwirren können, ein Phänomen, das als Verteilungsdrift bekannt ist.

Um diese Herausforderung zu meistern, haben wir in unserer Showcase-Installation ein starkes Studiolicht eingesetzt. Dies führte zu einer gleichmäßigen Beleuchtung und minimierte die Missinterpretationen des Modells.
Abschließend konnten wir erfolgreich demonstrieren, dass KI-gestützte Bildanalyse effektiv zur Erkennung und Lokalisierung von Anomalien im Aufbau von Lego-Vespa-Modellen eingesetzt werden kann. Trotz einiger Herausforderungen, wie der Bewältigung von Verteilungsdrift durch Beleuchtungsunterschiede, zeigt unsere Arbeit das immense Potenzial von Deep Learning in der Qualitätssicherung und Anomalieerkennung. Es bleibt jedoch ein fortlaufender Prozess, die Modelle weiter zu optimieren und an spezifische Anwendungsfälle anzupassen.



