
microTEC Südwest Clusterkonferenz: ATR Software zeigt innovative Ansätze
Am 15. und 16. Mai 2023 fand die inzwischen elfte Auflage der Clusterkonferenz des microTEC Südwest e. V. statt …
Am 15. und 16. Mai 2023 fand die inzwischen elfte Auflage der Clusterkonferenz des microTEC Südwest e. V. statt …
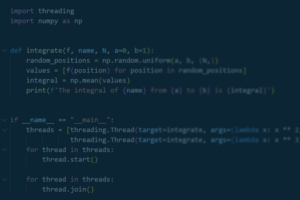
Interner Wissensaustausch ist ein wichtiger Faktor bei ATR Software. Deshalb haben wir die Vortragsreihe Wissen kompakt…
Sie sehen gerade einen Platzhalterinhalt von Vimeo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von hCaptcha laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von Turnstile laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr Informationen