Augmented Reality Forschung
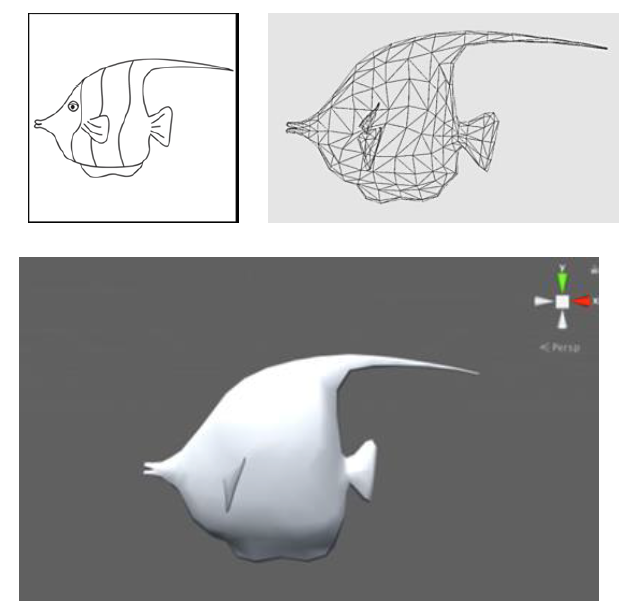
Von der Zeichnung zum Modell
Im September 2018 fand in Budapest im Rahmen einer Konferenz zum Thema Simulation die International Conference of the Virtual and Augmented Reality in Education statt. In diesem Beitrag werden nun drei Ideen und Projekte aus dieser Konferenz vorgestellt.
Im Feld von Design und Architektur wird Augmented Reality bereits seit einigen Jahren erfolgreich eingesetzt. Hierbei werden Entwürfe z.B. mittels AR Brillen betrachtet um ein besseres Gefühl für die Positionierung von Elementen im Raum zu erhalten. In einer Studie wurde gezeigt, dass diese Techniken einen Geschwindigkeits und Effektivitätsvorteil bieten [1].
Eine Forschergruppe aus Thailand entwickelte einen Ansatz, der es erlaubt Zeichnungen sehr schnell in 3D Modelle und damit in die virtuelle Welt zu transferieren. Ihren Anwendungsfall zeigten sie mit Hilfe von Fischzeichnungen, die in einem Virtuellem Aquarium zu leben erweckt wurden. [2]
Der letzte Ansatz beschreibt die Virtual Quality Toolbox, eine VR Anwendung, die es Angestellten in einer kleinen Produktion sehr einfach ermöglicht QS mit Virtual Reality zu bearbeiten. Hierbei werden vor allem Control-Charts, Histogramme, Paretodiagramme und Fishbone Diagramme (Ursache-Wirkungs-Diagramme) eingesetzt. [3]
——————————
[1] González et al.: The Impact of New Technologie in Design Education
[2] Boonbrahm et al.: Virtual Aquarium: Tool for Science Motivation using Augmented Reality
[3] Gorski et al..: Virtual Quality Toolbox